
Page 346 - AI Computer 10
P. 346
Let us understand each term one by one in detail.
Term Frequency
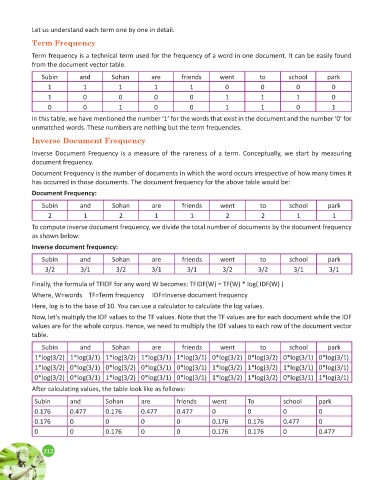
Term frequency is a technical term used for the frequency of a word in one document. It can be easily found
from the document vector table.
Subin and Sohan are friends went to school park
1 1 1 1 1 0 0 0 0
1 0 0 0 0 1 1 1 0
0 0 1 0 0 1 1 0 1
In this table, we have mentioned the number ‘1’ for the words that exist in the document and the number ‘0’ for
unmatched words. These numbers are nothing but the term frequencies.
Inverse Document Frequency
Inverse Document Frequency is a measure of the rareness of a term. Conceptually, we start by measuring
document frequency.
Document Frequency is the number of documents in which the word occurs irrespective of how many times it
has occurred in those documents. The document frequency for the above table would be:
Document Frequency:
Subin and Sohan are friends went to school park
2 1 2 1 1 2 2 1 1
To compute inverse document frequency, we divide the total number of documents by the document frequency
as shown below:
Inverse document frequency:
Subin and Sohan are friends went to school park
3/2 3/1 3/2 3/1 3/1 3/2 3/2 3/1 3/1
Finally, the formula of TFIDF for any word W becomes: TFIDF(W) = TF(W) * log( IDF(W) )
Where, W=words TF=Term frequency IDF=Inverse document frequency
Here, log is to the base of 10. You can use a calculator to calculate the log values.
Now, let’s multiply the IDF values to the TF values. Note that the TF values are for each document while the IDF
values are for the whole corpus. Hence, we need to multiply the IDF values to each row of the document vector
table.
Subin and Sohan are friends went to school park
1*log(3/2) 1*log(3/1) 1*log(3/2) 1*log(3/1) 1*log(3/1) 0*log(3/2) 0*log(3/2) 0*log(3/1) 0*log(3/1)
1*log(3/2) 0*log(3/1) 0*log(3/2) 0*log(3/1) 0*log(3/1) 1*log(3/2) 1*log(3/2) 1*log(3/1) 0*log(3/1)
0*log(3/2) 0*log(3/1) 1*log(3/2) 0*log(3/1) 0*log(3/1) 1*log(3/2) 1*log(3/2) 0*log(3/1) 1*log(3/1)
After calculating values, the table look like as follows:
Subin and Sohan are friends went To school park
0.176 0.477 0.176 0.477 0.477 0 0 0 0
0.176 0 0 0 0 0.176 0.176 0.477 0
0 0 0.176 0 0 0.176 0.176 0 0.477
212
212